
There are many reasons to convert audio files to text. You may want to search the file for a specific key word. The audio may be in a language that you do not understand. You may want to use the text for natural language processing tasks. Whatever the reason OpenAI’s whisper program can aid you in this endeavor.
OpenAI, the folks who brought you ChatGPT, developed whisper as a general purpose speech recognition model. Learn more about it here.
As with all Large Language Models (LLMs), it is better to use a GPU as they tend to be more computationally intensive. Free GPUs are available through google colab. Just select the GPU option when you connect to a runtime.
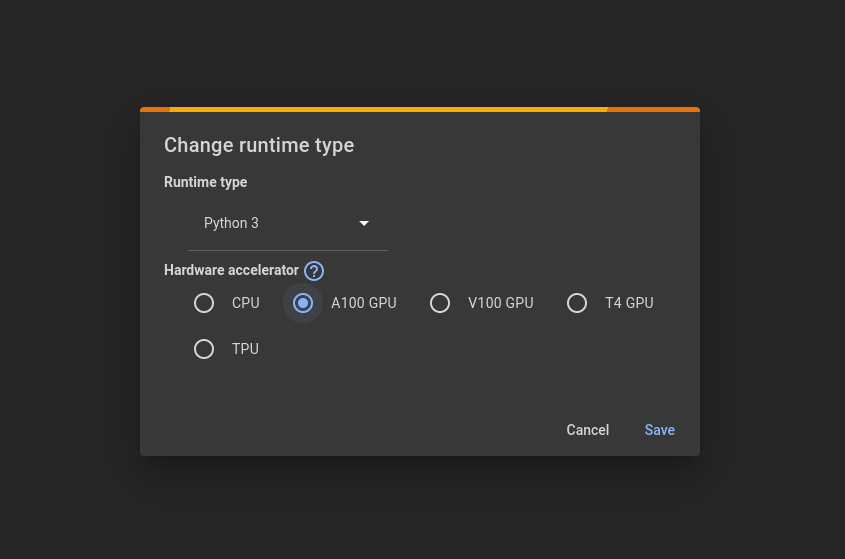
Then upload your audio file to google colab for use.
Next you will need to install openai-whisper in colab (or on your linux machine, exclude the !) with the following command.
!pip install -U openai-whisperNext you will import whisper, load a model, and transcribe your audio file. We will use the ‘medium’ model as it is a happy medium (lol) between efficiency and performance. You can read more about the models on the openai-whisper GitHub page.
import whisper
model = whisper.load_model("medium")
result = model.transcribe("file_name.mp3")Even on a GPU this may take some time to finish. Once complete you can save the audio transcription to a txt file with the following lines of code. (Don’t forget to download the file from colab to save it).
tf = open("file_name.txt", "w")
tf.write(result['text'])
tf.close()Whisper can also be run as a command line tool and has a translate function which can translate the audio as it transcribes it. Here is an example of a translation I did on a Putin speech I downloaded from here. Specify the language with the language tag and the translate tag will translate it to English. If you exclude the language tag it will just transcribe the audio into the specified language. I also specify the model as large which will produce better results but is computationally more intensive. (Remove the ! if you are running this command in a Linux terminal). This command will produce several files, the txt file is the translated transcript. Whisper supports a number of languages, read the docs to find out more.
!whisper putin.mp3 --language Russian --task translate --model large And there you have it! It really is that simple. You now have text that you can apply other analytical techniques to. Happy hunting!
